- Research article
- Open access
- Published:
The Total Deviation Index estimated by Tolerance Intervals to evaluate the concordance of measurement devices
BMC Medical Research Methodology volume 10, Article number: 31 (2010)
Abstract
Background
In an agreement assay, it is of interest to evaluate the degree of agreement between the different methods (devices, instruments or observers) used to measure the same characteristic. We propose in this study a technical simplification for inference about the total deviation index (TDI) estimate to assess agreement between two devices of normally-distributed measurements and describe its utility to evaluate inter- and intra-rater agreement if more than one reading per subject is available for each device.
Methods
We propose to estimate the TDI by constructing a probability interval of the difference in paired measurements between devices, and thereafter, we derive a tolerance interval (TI) procedure as a natural way to make inferences about probability limit estimates. We also describe how the proposed method can be used to compute bounds of the coverage probability.
Results
The approach is illustrated in a real case example where the agreement between two instruments, a handle mercury sphygmomanometer device and an OMRON 711 automatic device, is assessed in a sample of 384 subjects where measures of systolic blood pressure were taken twice by each device. A simulation study procedure is implemented to evaluate and compare the accuracy of the approach to two already established methods, showing that the TI approximation produces accurate empirical confidence levels which are reasonably close to the nominal confidence level.
Conclusions
The method proposed is straightforward since the TDI estimate is derived directly from a probability interval of a normally-distributed variable in its original scale, without further transformations. Thereafter, a natural way of making inferences about this estimate is to derive the appropriate TI. Constructions of TI based on normal populations are implemented in most standard statistical packages, thus making it simpler for any practitioner to implement our proposal to assess agreement.
Background
In an agreement assay, it is of interest to evaluate the degree of agreement between different methods (devices, instruments or observers) used to measure the same characteristic. Thus, the closeness between the measures of the methods must be evaluated. Different procedures for assessing agreement with continuous measurements have been proposed and these can be classified under two terms [1]: (1) unscaled summary indices based on absolute differences; and (2) scaled summary indices which translate absolute differences into more meaningful values ranging between -1 (perfectly reversed agreement) and 1 (perfect agreement), where 0 indicates no agreement.
Scaled indices have probably been the most widely used, especially the intraclass correlation coefficient [2–4] (ICC) and the concordance correlation coefficient [5] (CCC). Both ICC and CCC indices have recently been evaluated and compared in many studies [6–8], and have been shown to provide two different expressions of one common index. However, when conducting an agreement analysis it should be remembered that these scaled indices depend on the covariance between measurement devices [9], as the resulting estimates can vary depending on the possible range of values of the measurement instrument under consideration. Another consequence of this covariance dependency is that the indices might be overestimated if potential confounding variables are not taken into account [8].
Among unscaled procedures, the total deviation index (TDI) describes a boundary such that a majority percent of the differences in paired measurements are within the boundary [10, 11], i.e. a probability interval. The advantage of the TDI against scaled measures such as CCC is that it does not depend on the data range and therefore it avoids the inconvenience of not taking into account potential covariates that explain between-subject variation. However it must be noted that as in the CCC case the TDI will depend on covariates explaining within-subject variation. A further advantage is that it has a straightforward interpretation since it results in the same measurement scale as that of the variable considered for agreement purposes.
Several methods for inference about the TDI estimate have been proposed. To calculate the index Lin [10] derived the cumulative probability function of the square of the paired-measures difference variable, which is assumed to follow a non-central chi-squared distribution. He argues that inference about the estimate of the resulting equation is cumbersome, and he thus derives a further approximation with more desirable properties based on the asymptotic theory of the mean squared deviation (MSD) [10]. Lin et al. [12] extended the method to deal with repeated measures. Due to the positive skewness of the resulting TDI estimates, when performing inferences the natural log transformation of the estimate is used. This approximation has been shown to conclude satisfactory agreement when mean differences between two measurement devices are small, but it can be conservative when the relative bias square value is unreasonably large and when the coverage probability is large (0.95). Choudhary and Nagaraja [13] proposed an upper bound for the estimate of Lin's resulting TDI equation for the case of no repeated measures derived from an exact test. As the exact test method needs to maximise an integrated equation with no closed form, numerical computations are required to implement it; as the authors acknowledge, these may not be readily available in practice, so they also propose a closed-form approximation.
Choudhary [14] subsequently extended the method based on the asymptotic distribution of the logarithm of Lin's TDI proposal to deal with repeated measures. He argues that this method performs well with large sample sizes and proposes a modified version for smaller sample sizes based on a bootstrap approach. Recently, Quiroz and Burdick [15] also derived a method for inference about the TDI estimate when dealing with repeated measures for the two methods that are paired over time, and fit the data using an ANOVA model. They then construct generalised confidence intervals about the TDI estimate that are based on replacing parameters involved in Lin's [10] TDI expression with generalised pivotal quantities. The generalised confidence intervals are constructed via Monte Carlo simulations and have been shown to perform well in a wide range of scenarios, including those with either small, moderate or large sample sizes. Here we propose a technical simplification for inference about the TDI estimate based on a closed approach. We first estimate the TDI by finding the appropriate probability interval of the distribution of the paired-measures difference variable. Therefore, a natural way of making inferences about this TDI estimate is to derive its tolerance interval (TI). This procedure offers a straightforward approach as the theory and methods about TI for normal populations are well established [16–18].
The article is structured as follows: in the methods section the TDI is defined and Lin's [10] first approach is described. A brief description of two current closed approaches for inference about the TDI estimate is subsequently given. Thereafter, a probability interval approach is defined to obtain an alternative expression of the TDI estimate. This approach is also used to derive estimates of the inter- and intra-method [12, 19] measures of agreement when more than one reading per subject is available. Based on the probability interval approach a direct inference method about this estimate is derived via the TI. Lastly, in this section we also describe how one may utilize the TI approach to perform inference for the computation of the coverage probability, an agreement measure related to the computation of the TDI. In the results section we illustrate the methodology by using it to evaluate agreement between a manual and an automatic blood pressure device. In this example we point out the independence of the TI method from the effect of the between-subject variation, as compared with other scaled methods such as the CCC, whose covariate adjustment that explains between-subject variation modifies the resulting agreement value. We will also describe and report our simulation study procedure for evaluating the performance of the method and compare it to already established methods. A discussion and concluding remarks are given at the end of the manuscript.
Methods
Definition
Suppose a continuous variable is measured by two different devices m times each from n different subjects. Therefore, the data can be fit using the following mixed model [12, 14]:

where y
ijl
is the lth measurement from subject i by device j, with i = 1, ..., n, j = 1, 2, and l = 1, ..., m. δ is the vector of fixed effects parameters common to both devices and x
ijl
is the corresponding row of the design matrix for covariates, β
j
is the fixed device effect, α
i
is the individual random effect assuming that α
i
~ N(0,  ), γ
ij
is the individual-method interaction random effect with γ
ij
~ N(0,
), γ
ij
is the individual-method interaction random effect with γ
ij
~ N(0,  ) and e
ijl
is a random error assuming that e
ijl
~ N(0,
) and e
ijl
is a random error assuming that e
ijl
~ N(0, 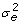 ) and is independent of any other component of the mixed model. If the error variability differs across devices, then e
ijl
~ N(0,
) and is independent of any other component of the mixed model. If the error variability differs across devices, then e
ijl
~ N(0,  ).
).
Lin [10] defined the TDI as a boundary, κ
p
, which captures a large proportion, p, of paired-measurement differences from two devices or observers within the boundary, i.e., the value of κ
p
that yields P(|D| < κ
p
) = p, where D is the paired-differences variate. Under the assumption of the mixed model in (1), D is the paired-differences variate based on any one of the replicates, D = (y
ijl
- y
ij'l'
), and hence κ
p
based on D is actually known as the total-TDI for evaluating total agreement [12]. It is shown that the distribution of D is then D ~ N(μ
D
, σ
D
) with μ
D
= β
j
- β
j'
and  , or in the case of different error variances between devices
, or in the case of different error variances between devices  .
.
When more than one reading per subject given by device j is available, one might be interested in measuring, in addition to the total agreement, the inter- and intra-method agreement [12, 19]. Intra-method indices are used to measure the agreement among the multiple readings obtained from the same device [12]. This agreement measure is useful when ones wishes to evaluate the reproducibility or repeatability of a specific device. To evaluate intra-method agreement, differences between replications from the same individual given by the j - th device are used and, therefore, under the assumption of the mixed model in (1): (y
ijl
- y
ijl'
) ~ N(0,  ) with = 2. Inter-method agreement is used to measure the agreement among different devices based on the average of their multiple readings [12]. If we denote
) with = 2. Inter-method agreement is used to measure the agreement among different devices based on the average of their multiple readings [12]. If we denote  , under the assumption of the mixed model in (1), the inter-method agreement can be evaluated by the following distribution: (y
ij. - y
ij'.) ~ N(μ
D
,
, under the assumption of the mixed model in (1), the inter-method agreement can be evaluated by the following distribution: (y
ij. - y
ij'.) ~ N(μ
D
,  ), where μ
D
= β
j
- β
j'
and
), where μ
D
= β
j
- β
j'
and  , or in the case of different error variances between devices,
, or in the case of different error variances between devices,  .
.
The first formal definition [10] of the TDI for the case of one single reading from each device for each subject, i.e when m = 1, was based on the distributional assumption of the square transformation of the paired-measurement difference variable:

where F
-1 is the inverse of the cumulative probability function of |D|, and χ
2(-1)(·) is the p-th percentile of a non-central chi-square distribution with 1 degree of freedom and non-centrality parameter  . Even though equation (2) was defined for the case of one single reading, one can apply the mixed model (1) to accommodate replicated readings from each device for each subject and use the model parameter estimates to obtain estimates of μ
D
and
. Even though equation (2) was defined for the case of one single reading, one can apply the mixed model (1) to accommodate replicated readings from each device for each subject and use the model parameter estimates to obtain estimates of μ
D
and  and, furthermore, compute the TDI estimate by plugging in these estimates [14]. However, and as Lin [10] argued, inference about this κ
p
estimate is cumbersome, and he therefore proposed a further approximation based on the mean squared deviation (MSD):
and, furthermore, compute the TDI estimate by plugging in these estimates [14]. However, and as Lin [10] argued, inference about this κ
p
estimate is cumbersome, and he therefore proposed a further approximation based on the mean squared deviation (MSD):

where ε 2 = E(y ijl - y ij'l' )2, z (1 + p)/2 is the (1 + p)/2 - th percentile of the standard normal distribution and |·| is the absolute value.
Current approaches for inference about the TDI estimate
There are two already existing closed procedures for inference about the TDI estimate that consider repeated measures taken by each of the two devices with multiple readings being compared. The first approach was defined by Lin et al. [12] where the authors expressed the TDI approximation based on the MSD, as in (3), which under the assumption of the mixed model in (1) the MSD becomes  , and therefore
, and therefore  , where
, where  = (β
j
- β
j'
)2/2 is defined as the variance between the two devices. Furthermore, the generalized estimating equations (GEE) approach [20] is used to obtain the model parameter estimates in (1). Since this TDI estimate is positively skewed [11, 12] the authors use the log transformation to form inference and the delta method is applied to obtain the variance of the resulting TDI estimate.
= (β
j
- β
j'
)2/2 is defined as the variance between the two devices. Furthermore, the generalized estimating equations (GEE) approach [20] is used to obtain the model parameter estimates in (1). Since this TDI estimate is positively skewed [11, 12] the authors use the log transformation to form inference and the delta method is applied to obtain the variance of the resulting TDI estimate.
The second approach was defined by Choudhary [14] where the author proposes to use the maximum likelihood estimation (MLE) procedure to obtain model parameter estimates in (1) and, furthermore, compute the TDI estimate by simply plugging the MLE estimates of μ
D
and in (2). The author argues that the distribution of this MLE estimate of the TDI approach normality more quickly on the log scale, especially when the sample size is small. Based on this assumption the delta method is used to obtain the variance of the log-transformed TDI estimate.
Both approaches for inference about the TDI estimate are based on the delta method, which means that one should first find the partial derivatives of the log transformed TDI with respect to the model parameters used to obtain the expression of the TDI and then find the inverse of the information matrix for the fitted model.
TDI as a probability interval
Consider the TDI definition, which sets a boundary such that a majority p percent of the differences in paired observations are within the boundary: P(|D| < κ p ) = p. This is the same as finding κ p , such that P(-κ p < D < κ p ) = p. Thus, [-κ p ; κ p ] defines the probability interval of D centered at 0, regardless of the mean value of D. Since D is assumed to behave as a normal distribution with mean μ D and standard deviation σ D , one can derive κ p using standard methods for computing probability intervals:

where  , s = 1, 2, are the p
s
-th percentile of the standard normal distribution, such that
, s = 1, 2, are the p
s
-th percentile of the standard normal distribution, such that  = -2μ
D
/σ
D
-
= -2μ
D
/σ
D
- 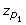 and p
1 - p
2 = p. Therefore, one can find p
1 by using its link with p:
and p
1 - p
2 = p. Therefore, one can find p
1 by using its link with p:

where Φ(·) is the cumulative standard normal distribution.
However, p 1 cannot be found in a closed form using equation (5), so a recursive algorithm is required. We propose to use a modified version of the binary search algorithm [21] to find p 1 and, furthermore, to compute κ p using (4).
Typically, the binary search algorithm is used to search in an ordered array for a single element by repeatedly dividing the array in half. Here we translate the ordered array into the interval [low; high], which means that low(high) is the lowest(highest) value that p 1 can take. Now, since equation (5) has a single solution for p 1 in the interval [p; 1], one can repeatedly halve the interval in an adequate manner to find the optimum for p 1. Therefore, the algorithm is implemented as follows:
-
1.
begin with the interval [low = p; high = 1];
-
2.
calculate the midpoint of the interval mid = (low + high)/2;
-
3.
if the left-hand side of equation (5) for p i = low is greater than p up to a tolerance bound δ (i.e.,
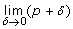 ), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than p up to a tolerance bound δ (i.e.
), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than p up to a tolerance bound δ (i.e. 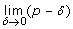 ), then recalculate the interval [low = p; high = mid - δ];
), then recalculate the interval [low = p; high = mid - δ]; -
4.
repeat steps 2-3 until convergence, i.e. until the solution for p 1 in (5) is p - δ < Φ(z p1) - Φ(-2μ D /σ D -
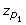 ) < p + δ.
) < p + δ.
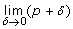 ), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than p up to a tolerance bound δ (i.e.
), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than p up to a tolerance bound δ (i.e. 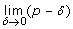 ), then recalculate the interval [low = p; high = mid - δ];
), then recalculate the interval [low = p; high = mid - δ];The advantage of using this iterative algorithm is its speed, as it converges on the true value of p 1 in a logarithmic order of growth.
This probability interval procedure ensures that the lower bound of the interval is symmetric with the upper bound about 0; therefore it is only necessary to search for one of the interval's two limits, as the other is symmetrical about zero.
We propose to use the restricted maximum likelihood estimation (REML) method [22] to obtain the model parameter estimates in (1) and furthermore compute the TDI estimate based on probability intervals by plugging in the REML estimates of μ D and σ D in (4).
We must note that this resulting estimate of the TDI yields the same estimate as that directly computed from equation (2) using the sample counterparts, however as we will illustrate in subsequent sections this binary search algorithm is necessary to compute our proposal for the upper confidence limit of TDI.
Intra- and inter-method TDI
The TDI based on probability intervals can also be used to assess inter- and intra-method agreement measures.
To evaluate intra-method agreement, we use the difference between two replications for the i - th individual given by the j - th device and, therefore, under the assumption of the mixed model in (1): (y
ijl
- y
ijl'
) ~ N(0, ). Now, since the probability distribution is centered at 0, the TDI can easily be derived via a probability interval:

In fact, this resulting approach corresponds to the ISO definition of the standard way of measuring the reproducibility or repeatability of a device for the specific case where the 95thpercentile point of the standard normal is used for z (1+p)/2 [23].
If the variability differs across devices one should then obtain two different intra-method agreements as  , with j = 1, 2.
, with j = 1, 2.
Inter-method agreement can be evaluated by the following distribution: (y
ij· - y
ij'
) ~ N(μ
D
, ), and therefore:

where p 1 is found by using the modified binary search algorithm detailed previously.
A tolerance interval (TI) for inference about the TDI estimate
Our proposal for inference about the TDI estimate is based on tolerance intervals (TI), provided that we estimate the TDI by deriving the limits of a probability interval that contains a specified p-proportion of the resulting estimated normal distribution.
Now, since we use estimates of the normal distribution parameters of D instead of using true values, κ p is obtained by replacing μ D and σ D by their REML estimate counterparts derived from model (1) in expression (4):

Therefore, a natural way of making inference about  is to compute a one-sided tolerance interval [17, 18] that covers the p
1-percent of the population from D with a stated confidence. This is analogous to computing a one-sided confidence interval for the limit that defines the one-sided probability interval which contains the p
1-percent of the population of the estimated distribution of D, where p
1 is found using the modified binary search algorithm.
is to compute a one-sided tolerance interval [17, 18] that covers the p
1-percent of the population from D with a stated confidence. This is analogous to computing a one-sided confidence interval for the limit that defines the one-sided probability interval which contains the p
1-percent of the population of the estimated distribution of D, where p
1 is found using the modified binary search algorithm.
Thus, let T be the studentized variable of  . It is shown, then, that T follows a non-central Student-t distribution with non-centrality parameter
. It is shown, then, that T follows a non-central Student-t distribution with non-centrality parameter  :
:

where N = 2 × n × m is the total possible paired-measurement differences between the two devices. The degrees of freedom, ν, are derived from the residual degrees of freedom. We have adopted here the conservative situation, as ANOVA (analysis of variance) philosophy (see for example Searle et al. [24]), where all fixed and random effects consume degrees of freedom and, therefore, ν = 2 × n × (m - 1). If there is no individual-device interaction, then the degrees of freedom are ν = 2 × n × m - (n + m - 1). However one can also adopt a less restrictive position and consider that the random effects do not consume degrees of freedom and in that case ν = 2 × n × m - 2. In situations where the variability differs across devices, the error variance of the difference between paired measurements is obtained as a linear combination of the two residual variance estimates, so the degrees of freedom can be achieved more efficiently using the Satterthwaite adjustment [25].
One can therefore construct an upper bound (UB) for the TDI estimate by using the following cf = (1 - α) × 100% one-sided TI, where α is the type I error rate:

This TI corresponds to the exact one-sided tolerance interval for at least p 1 proportion of the population defined by Hahn [17] and Hahn and Meeker [18].
For computing the above TDI approach, a SAS macro and an R function are available in additional file 1. The same rationale is used to construct an upper bound for the intra- and inter-method TDI estimates derived from plugging the REML estimates from expression (1) into expressions (6) and (7), respectively. The upper bounds are constructed as in the following expressions:


One can also adopt the TI defined in expressions (10), (11) or (12) to perform a hypothesis test if the interest is to ensure that at least p-percent of the absolute differences between paired measurements are less than a predetermined constant κ 0. Therefore, the null hypothesis would be defined as in Lin [10], and take the form

and H 0 would be rejected with a type I error α if

where one should use the appropriate  and
and  if the hypothesis test is constructed to evaluate total-, intra- or inter-method TDI.
if the hypothesis test is constructed to evaluate total-, intra- or inter-method TDI.
Coverage probability (CP)
Another user friendly measure of agreement which is related to the computation of the TDI is the so called coverage probability (CP) [11, 12]. The CP describes the proportion captured within a pre-specified boundary of the absolute paired-measurement differences from two devices, i.e., the value of p κ such that P(|D| < κ) = p κ . Therefore one can find p κ for a specified boundary κ using standard methods for computing probability quantities under normal assumptions [11]:

and to obtain a CP estimate, p κ can be computed by replacing μ D and σ D by their REML estimate counterparts derived from model (1).
As with the TDI, the CP criterion can also be translated into a hypothesis test specification. In this case the interest is to ensure that a specified boundary of the absolute paired-measurement differences captures at least a predetermined proportion, p 0:

The proposed TI method for inference about the TDI can be utilized to perform inferences about the CP estimates. From the TI in (10) it follows that

Now κ is a fixed known boundary, and our interest lies in finding a lower confidence bound for the CP estimate. Thus, one can find a lower confidence bound for a non-central Student-t proportion with confidence level 1 - α by searching the non-centrality parameter, that depends on and hence on p
κ
, that satisfies

and once the non-centrality parameter is achieved, a lower bound about the proportion p
κ
is found using equation (5), p
κ
= Φ() - Φ(-2μ
D
/σ
D
- ).
However, the non-centrality parameter cannot be found in a closed form, so one may use again a modified version of the binary search algorithm as follows:
-
1.
begin with the interval [low = 0; high = 1], as p κ is bounded by the interval (0,1);
-
2.
calculate the midpoint of the interval mid = (low + high)/2 and compute the difference
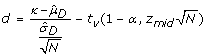 ;
; -
3.
if d is greater than 0 up to a tolerance bound δ (i.e.,
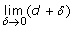 ), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than 0 up to a tolerance bound δ (i.e.
), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than 0 up to a tolerance bound δ (i.e. 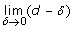 ), then recalculate the interval [low = 0; high = mid - δ];
), then recalculate the interval [low = 0; high = mid - δ]; -
4.
repeat steps 2-3 until convergence, i.e. until d satisfies
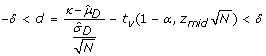 .
.
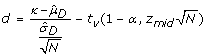 ;
;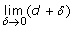 ), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than 0 up to a tolerance bound δ (i.e.
), then recalculate the interval [low = mid + δ; high = 1]; if it is lower than 0 up to a tolerance bound δ (i.e. 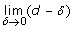 ), then recalculate the interval [low = 0; high = mid - δ];
), then recalculate the interval [low = 0; high = mid - δ];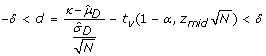 .
.Results
Case-example: blood pressure device data
The method proposed here to assess agreement using the TDI measure will now be illustrated in a real case example. We will also show that the independence of the method from the effect of the covariance between devices (between-subject variability) constitutes an advantage of unscaled over scaled indices such as the CCC.
A sample of 384 subjects was collected and measures of systolic blood pressure were taken via two instruments: a handle mercury sphygmomanometer device and an OMRON 711 automatic device. The systolic blood pressure was measured twice by each instrument. Gender, age and heart rate were also recorded as covariates.
A Bland-Altman plot is shown in Figure 1. It can be seen that measurements taken from the handle sphygmomanometer tend to be discretized in round values of 10 units each, while measurements from the automatic instrument are dispersed around the range of values of the systolic blood pressure. As a result of discussions with clinical practitioners, one can assume that the manual instrument can be replaced by the automatic device if a large proportion of paired-measurement differences are within a boundary of 10 mmHg. Under this hypothesis the TDI measure is appropriate for making such a decision.

Blood pressure device data. Bland and Altman plot of systolic blood pressure measured using automatic device (OMRON 711) and handle device (mercury sphygmomanometer). The total possible paired-measurements are represented.
We first fit the mixed model with 'measurement device' as the fixed effect and 'individual' and 'individual-device interaction' as random effects (Model 1, Table 1) and thereafter we excluded the 'individual-device interaction' in a second model which produced a similar fit (Akaike Information Criterions (AIC): AIC
Model1 = 11764.83 vs. AIC
Model2 = 11760.83). The resulting estimates of  = 10.283 and = 2.174 are used to obtain the TDI estimate. Assuming that the TDI should contain at least a proportion of 0.90 of the paired measurements between devices, the TDI estimate was 17.29 and its corresponding one-sided 95% TI was 17.93 (TDI estimates for proportions of 0.80, 0.85 and 0.95 are shown in Table 2). The TI's were calculated using a tolerance bound of 1e-10 and the computed values of p
1 for proportions of 0.80, 0.85, 0.90 and 0.95 were 0.864, 0.896, 0.929 and 0.963 respectively.
= 10.283 and = 2.174 are used to obtain the TDI estimate. Assuming that the TDI should contain at least a proportion of 0.90 of the paired measurements between devices, the TDI estimate was 17.29 and its corresponding one-sided 95% TI was 17.93 (TDI estimates for proportions of 0.80, 0.85 and 0.95 are shown in Table 2). The TI's were calculated using a tolerance bound of 1e-10 and the computed values of p
1 for proportions of 0.80, 0.85, 0.90 and 0.95 were 0.864, 0.896, 0.929 and 0.963 respectively.
We also applied Lin's and Choudhary's procedures described in the methods section; the second produced the same results as our TI proposal and Lin's approach resulted in more conservative estimates compared to the respective percentiles calculated from the absolute difference. Though these percentiles are naive estimates of the TDI's, they can serve as the reality check for comparing across the three methods, since we do not know the theoretical values. Based on the three methods applied, under the hypothesis of disagreement between devices, if a large proportion of absolute paired-measurement differences are above a boundary of 10 we would not reject disagreement, thus the two devices are not interchangeable.
We then entered gender, age and heart rate as covariates into the model. The inclusion of covariates in the model did not modify the parameter estimates used to calculate the TDI, i.e. the device fixed-effect and the error variance estimates, and therefore the TDI estimates as well as their 95% one-sided TI remain the same.
Finally, we also calculated the intra- and inter-method TDI containing 80%, 85%, 90% and 95% proportions, as shown in Table 2. The intra-method TDI is interpreted as the boundary at which the specified proportion of the replicated measurements are furthest from themselves. The inter-method TDI is interpreted as the boundary at which the specified proportion of the average of the replicated measurements from one device are furthest from the average of the replicated measurements of the other device. In the case example, for all four proportions specified, the intra-method TDIs are larger than the pre-specified boundary of a difference of at least 10 to ensure agreement (the difference observed between Lin's and our TI proposal is due to the estimation method of the variance components), which means that the principal problem with the total-TDI is due to the fact that the intra-individual variability is too large rather than the systematic bias. In other words, if one calibrates both devices, i.e., in the absence of bias, the devices would still not be interchangeable. Therefore a specific device for measuring the systolic blood pressure is not interchangeable with itself and it is somewhat pointless to assess agreement between these two devices since they are not repeatable within themselves.
Simulation study
The performance of the method to evaluate agreement via the TDI estimate using probability intervals, as well as inference via the TI approach, will be assessed and compared to the two already established methods by means of a simulation study.
The scenario is based on the real case example of blood pressure device data where two measures for each of the two devices are simulated. For the sake of simplicity we assumed, as in the case-example, no interaction effect between individuals and devices. We therefore held fixed the intercept and the variance component of the individual random effect equal to the mixed-model point estimates in the original data (Table 1, Model 2), while we simulated different combinations of fixed device effects and random error variance. We first considered a device effect equal to the point estimate obtained from the original data (2.174), and then simulated two other more extreme values: a mean difference of 0 and a larger mean difference of 5. Likewise, we simulated a random error variance equal to the case-example point estimate (52.867), which gives a standard deviation of the difference between devices of 10.283, and then simulated a smaller random error variance of 16, which gives a standard deviation for the paired differences around half the value obtained in the original case-example data (5.65). Sample sizes of 20 and 100 individuals were considered. For each scenario considered, the simulation study involved generating 1000 samples of the measurements vector with the particular structure. The algorithm used to generate the s - th (s = 1, ..., 1000) sample can be summarised in the following steps:
-
1.
set δ and
 and set values for β and
and set values for β and 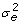 ;
; -
2.
generate each measurement data vector y sfrom the multivariate normal distribution MV N(X(δ, β)t, V(
, )); -
3.
fit the mixed model for each data set using GEE when Lin's approach is applied, MLE for Choudhary's approach and REML for our proposal.
Note that the parameters of the multivariate normal distribution in step 2 come from the matrix notation of the mixed model described above, where X is the design matrix of the fixed effects and V is the block-diagonal total variance-covariance matrix with diagonal elements equal to  and off-diagonal elements equal to .
and off-diagonal elements equal to .
The TDI point estimate via probability intervals and their corresponding TI were computed for each case, with a tolerance equal to 1.0e-4, as well as Lin's and Choudhary's proposals.
The accuracy of the TDI estimate was calculated in order to determine whether the TI was reliable. Thus,
we calculated the mean of the TDI estimates and the mean square error, MSE = E( - κ
p
)2, where the actual κ
p
is calculated using Lin's [10] definition, as in equation 2.
To evaluate the performance of the TI approach for inference about the TDI estimate we analyzed the empirical confidence (EC) of the TI as  , where I
s= 1 if κ
p
is within the TI. The same rationale was applied for the two other established methods.
, where I
s= 1 if κ
p
is within the TI. The same rationale was applied for the two other established methods.
Since the distribution property of a TDI estimate has been shown to be log-normal [11, 12], the mean and MSE are computed based on the log transformation of the TDI estimates, and the EC are directly computed from the upper limits of the log transformed TDI estimates.
Table 3 shows that good point estimates of the TDI are obtained in all of the simulated combinations; however, the small MSEs found increase in line with the difference between devices, the standard deviation of the differences, and the proportion of the population that should be contained within the TDI boundary increase. The fact that the MSE is lower for larger sample sizes indicates the consistent asymptotic properties of the probability interval estimation approach. It is also shown that in simulations based on no difference between devices, a systematic, slight overestimation is found in TDI point estimates.
ECs, for each scenario combination, evaluating the 95% nominal coverage of the TI approach, are shown in Table 3. The results show that the TI approximation produces accurate coverage rates which are reasonably close to the nominal coverage. It should be highlighted that combinations with higher EC are those based on a mean difference between devices of 0. This is a result of the systematic overestimation of the TDI. At the other extreme, simulations based on mean differences of 5 and small standard deviation for paired differences show a EC lower than the desired 95% nominal coverage, although this is only observed in cases with small sample sizes. However, the coverage rates do increase towards the nominal coverage with larger sample sizes.
Simulation results of the current approaches are also shown in Table 3. Choudhary's proposal seems to produce the most stable results in terms of EC in all the scenarios simulated, however the range of the estimated TDI upper bounds are very similar to our TI approach (Figure 2), the difference is only seen in scenarios simulated with a mean difference of 0, even though the boxplots in these situations are shifted up in the worst case by no more than 0.5 units. Lin's approach results in intermediate values between Choudhary's results and our TI proposal results for these specific scenarios. However Lin's upper bounds of the TDI estimates seem to increase in line with larger mean difference, stated proportions and sample size (Figure 2). This issue is in accordance with the results found in [12] where the authors also recognized that their approximate TDI can be conservative when the relative bias square value is unreasonably large and when the coverage probability is large (>0.9).

Simulation results: upper bounds of the TDI estimates. Boxplots of the upper bounds of the TDI estimates (UB(TDI)) based on Choudhary (Ch), Lin (L) and our Tolerance Interval (TI) approaches for each of the scenarios considered. Horizontal lines refer to the actual TDI simulated based on the four different proportion sets (80%, 85%, 90% and 95%).
Discussion
With the aim of assessing agreement between two devices of continuous measurements via the total deviation index (TDI), the present study evaluated the performance of a simplified technical approximation of the TDI based on probability intervals and a tolerance interval (TI) approach for inference about the resulting TDI estimate.
The parameters involved in the TDI are obtained from a linear mixed effects model estimated via REML. The linear mixed model has the advantage of its flexibility that allows adapting the model to the data features as replicates.
Several methods have been implemented for making inferences about the TDI estimate [10, 12–15, 26]. However, since all these methods are based on the square transformation of the paired-measures difference variable, which makes exact inference about the resulting estimate difficult, inference is carried out using analytical approaches or methods based on Monte Carlo simulations.
Bland and Altman [27, 28] also defined an unscaled agreement index known as limits of agreement, which is similar to the TDI. The authors derive the limits as boundaries, such that a majority percent of the paired-measurement differences fall within the boundaries using a probability interval, and thereafter they derive a TI for inference about the limits. However, since the intervals are constructed to be symmetrical about the mean difference, and not symmetrical about 0, the TDI could be constructed by taking the maximum of the absolute value among lower and upper limits: max(|L low |, |L upp |). Conversely, the initial percent that is assumed to fall within the boundaries would result in a larger proportion thereafter. The proposal introduced here corrects this fact and, as a result, the "effective length" of the interval is shortened.
We have also shown in the present study how the proposed method can be used to compute bounds for the coverage probability (CP). As the computation of CP is related to the computation of the TDI, the performance of the CP bound behaves very similarly to the TDI bound (results from a simulation analysis are shown in additional file 2).
Although our proposal has been shown to provide accurate empirical confidences it does tend to overestimate the nominal confidence level slightly, especially for small differences between devices. In terms of hypothesis testing this means that the type I error will be smaller than the desired nominal rate in this particular scenario. In agreement assays were the aim lies in evaluating if one currently used device can be replaced by another one, as in our case example, this might be a benefit since it means that replacing a good device by a bad device is very unlikely. This issue was already detected by Westlake [29], who proposed a modification of the conventional confidence interval method to obtain symmetrical confidence intervals around 0 for bioequivalence trials. The limits of the confidence intervals were constructed in the same manner as proposed here to obtain the probability intervals to estimate the TDI. Westlake demonstrated that the confidence level constructed in this way is 100% for a mean difference of 0 and larger sample size, decreasing monotonically to the desired nominal confidence as the difference tends to infinity. A limitation of our proposal is seen when the mean difference between devices is large compared to the standard deviation and the sample size is small, in these situations the type I error will be slightly larger than the desired nominal rate.
Conclusions
Finally, we would like to highlight that the method proposed here is straightforward since the TDI estimate is derived directly from a probability interval of a normally-distributed variable in its original scale, without further transformations. Thereafter, a natural way of making inferences about this estimate is to derive the appropriate TI. The expression of our TI proposal corresponds to the exact one-sided TI defined by Hahn in 1970 [17] for at least a pre-specified proportion of a normally distributed population, with the particularity that the specified proportion is found using a search algorithm to ensure the confidence bounds be symmetrical about 0. This procedure has been shown to provide accurate coverage rates, even though it is slightly more conservative than Lin's and Choudhary's approaches in the case of no systematic bias, which both show results closer to the nominal confidence level. However the TI results in these situations are reasonably close to those given by these other established methods. At the other extreme, when there is a large bias compared to the standard deviation and the sample size is small, the empirical confidence is slightly smaller than the stated nominal confidence, but again the TI results are very close to those given by Choudhary's proposal which appears to be the most stable approach in terms of empirical coverage in this situation. The advantage of our proposal is that constructions of TI are implemented in most standard statistical packages, thus making it simpler for any practitioner to implement it to assess agreement.
References
Barnhart HX, Haber MJ, Lin LI: An overview on Assessing Agreement with continuous Measurements. Journal of Biopharmaceutical Statistics. 2007, 17: 529-569. 10.1080/10543400701376480.
Pearson K: Mathematical distributions to the theory of evolution. Philosophical Transactions of the Royal Society of London, Series A. 1901, 197: 385-597.
Bartoko JJ: The intraclass correlation coefficient as a measure of reliability. Sychological Reports. 1996, 19: 3-11.
Fleiss JL, Shrout PE: Approximate interval estimation for a certain intraclass correlation coefficient. Psychometrika. 1978, 43: 259-262. 10.1007/BF02293867.
Lin LI: A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics. 1989, 48: 599-604. 10.2307/2532314.
Nickerson CAE: Comment on "A Concordance Correlation Coefficient to Evaluate Reproducibility". Biometrics. 1997, 53: 1503-1507. 10.2307/2533516.
Robieson WZ: On the weighted kappa and concordance correlation coefficient. PhD thesis. 1999, University of Illinois
Carrasco JL, Jover L: Estimating the Generalized Concordance Correlation Coefficient through Variance Components. Biometrics. 2003, 59: 849-858. 10.1111/j.0006-341X.2003.00099.x.
Atkinson G, Neville A: Comment on the use of concordance correlation to assess agreement between two variables. Biometrics. 1997, 53: 775-778.
Lin LI: Total deviation index for measuring individual agreement with applications in laboratory performance and bioequivalence. Statistics in Medicine. 2000, 19: 255-270. 10.1002/(SICI)1097-0258(20000130)19:2<255::AID-SIM293>3.0.CO;2-8.
Lin LI, Hedayat AS, Sinha B, Yang M: Statistical methods in assessing agreement: models, issues, and tools. Journal of the American Statistical Association. 2002, 97: 257-270. 10.1198/016214502753479392.
Lin LI, Hedayat AS, Wu W: A unified approach for assessing agreement for continuous and categorical data. Journal of Biopharmaceutical Statistics. 2007, 17: 629-652. 10.1080/10543400701376498.
Choudhary PK, Nagaraja HN: Tests for assessment of agreement using probability criteria. Journal of Statistical Planning and Inference. 2007, 138 (4): 1102-1115. 10.1016/j.jspi.2007.03.056.
Choudhary PK: A tolerance interval approach for assessment of agreement in method comparison studies with repeated measurements. Journal of Statistical Planning and Inference. 2008, 138: 1102-1115. 10.1016/j.jspi.2007.03.056.
Quiroz J, Burdick RK: Assessment of Individual Agreements with Repeated Measurements Based on Generalized Confidence Intervals. Journal of Biopharmaceutical Statistics. 2009, 19 (2): 345-359. 10.1080/10543400802622576.
Howe WG: Two-sided Tolerance Limits for Normal Populations-Some improvements. Journal of the American Statistical Association. 1969, 64: 610-620. 10.2307/2283644.
Hahn GJ: Statistical Intervals for a Normal Population, Part I. Tables, Examples and Applications. Journal of Quality Technology. 1970, 2: 115-125.
Hahn GJ, Meeker WQ: Statistical Intervals: A Guide for Practitioners. 1991, New York: John Wiley & Sons, Inc
Barnhart HX, Song J, Haber MJ: Assessing intra, inter and total agreement with replicated readings. Statistics in Medicine. 2005, 24: 1371-1389. 10.1002/sim.2006.
Hardin JW, Hilbe JM: Generalized Estimating Equations. 2003, London: Chapman & Hal/CRCl
Knuth D: The Art of Computer Programming, Sorting and Searching. 1997, Massachusetts: Addison-Wesley, 3:
McCulloch CE, Searle SR: Generalized, Linear, and Mixed Models. 2001, Canada: Wiley Series in Probability and Statistics
ISO: Accuracy (trueness and precision) of measurement methods and results - Part 2: Basic method of the determination of repeatability and reproducibility of a standard measurement method. 1994, 5725-2.
Searle RS, Casella G, McCulloch CE: Variance Components. 2006, New York: Wiley
Littell RC, Milliken GA, Stroup WW, Wolfinger RD, Schabenberger O: SAS for Mixed Models. 2006, Cary, NC: SAS Institute Inc
Choudhary PK: A tolerance interval approach for assessment of agreement with left censored data. Journal of Biopharmaceutical Statistics. 2007, 17: 583-594. 10.1080/10543400701329430.
Bland JM, Altman DG: Statistical methods for assessing agreement between two methods of clinical measurement. Lancet. 1986, i: 307-317.
Bland JM, Altman DG: Measuring agreement in method comparison studies. Statistical Methods in Medical Research. 1999, 8: 135-160. 10.1191/096228099673819272.
Westlake WJ: Symmetrical Confidence Intervals for Bioequivalence Trials. Biometrics. 1976, 32 (4): 741-744. 10.2307/2529259.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2288/10/31/prepub
Acknowledgements
The authors thank the reviewers for their constructive comments that substantially enhanced the article.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests
Authors' contributions
GE and JLC conceived, designed and performed the analysis. GE, JLC and CA were responsible of the interpretation of the results and drafting the paper. All authors read and approved the final manuscript.
Electronic supplementary material
12874_2009_434_MOESM1_ESM.PDF
Additional file 1: Software codes. Description of a SAS macro and an R function developed to compute the TDI estimate and upper confidence bound. (PDF 17 KB)
12874_2009_434_MOESM2_ESM.PDF
Additional file 2: 2CP simulation results. Simulation results about the performance of the coverage probability (CP) index. (PDF 102 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Escaramís, G., Ascaso, C. & Carrasco, J.L. The Total Deviation Index estimated by Tolerance Intervals to evaluate the concordance of measurement devices. BMC Med Res Methodol 10, 31 (2010). https://doi.org/10.1186/1471-2288-10-31
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2288-10-31