- Research article
- Open access
- Published:
Parametric versus non-parametric statistics in the analysis of randomized trials with non-normally distributed data
BMC Medical Research Methodology volume 5, Article number: 35 (2005)
Abstract
Background
It has generally been argued that parametric statistics should not be applied to data with non-normal distributions. Empirical research has demonstrated that Mann-Whitney generally has greater power than the t-test unless data are sampled from the normal. In the case of randomized trials, we are typically interested in how an endpoint, such as blood pressure or pain, changes following treatment. Such trials should be analyzed using ANCOVA, rather than t-test. The objectives of this study were: a) to compare the relative power of Mann-Whitney and ANCOVA; b) to determine whether ANCOVA provides an unbiased estimate for the difference between groups; c) to investigate the distribution of change scores between repeat assessments of a non-normally distributed variable.
Methods
Polynomials were developed to simulate five archetypal non-normal distributions for baseline and post-treatment scores in a randomized trial. Simulation studies compared the power of Mann-Whitney and ANCOVA for analyzing each distribution, varying sample size, correlation and type of treatment effect (ratio or shift).
Results
Change between skewed baseline and post-treatment data tended towards a normal distribution. ANCOVA was generally superior to Mann-Whitney in most situations, especially where log-transformed data were entered into the model. The estimate of the treatment effect from ANCOVA was not importantly biased.
Conclusion
ANCOVA is the preferred method of analyzing randomized trials with baseline and post-treatment measures. In certain extreme cases, ANCOVA is less powerful than Mann-Whitney. Notably, in these cases, the estimate of treatment effect provided by ANCOVA is of questionable interpretability.
Background
Introductory statistics textbooks typically advise against the use of parametric methods, such as the t-test, for the analysis of randomized trials unless data approximate to a normal distribution. Altman, for example, states that "parametric methods require the observations within each group to have an approximately Normal distribution ... if the raw data do not satisfy these conditions ... a non-parametric method should be used" [1]. In some cases, central limit theorem is invoked such that parametric methods are said to be applicable if sample size is suitably large: "for reasonably large samples (say, 30 or more observations in each sample) ... the t-test may be computed on almost any set of continuous data" [2].
The rationale for recommending non-parametric over parametric methods, unless certain conditions are met, is rarely made explicit. But techniques for statistical inference from randomized trials can only fail in one of two ways: they can inappropriately reject the null hypothesis of no difference between groups (false positive or Type I error) or inappropriately fail to reject the null (false negative or Type II error). Hence any recommendation to favor one technique over another must be based on the relative rates of these two errors.
Empirical statistical research has clearly demonstrated that the t-test does not inflate Type I (false positive) error. In a typical study, Heeren et al examined the properties of the t-test to analyze small two-group trials where data are ordinal, such as from a five point scale, and thus non-normal [3]. They found that where there was truly no difference between groups, the t-test would reject the null hypothesis close to 5% of the time.
Thus concern over the relative advantages of parametric and non-parametric methods has focussed on Type II error [4]. Typically, researchers have created a large number of data sets, in which observations were created from a distribution incorporating a difference between groups. Each data set is then analyzed by both parametric and non-parametric methods in order to calculate the proportion of times the null hypothesis is rejected (that is, the power) [5–7].
The results have been fairly consistent. Where data are sampled from a normal distribution, the t-test has very slightly higher power than Mann-Whitney, the non-parametric alternative. However, when data are sampled from any one of a variety of non-normal distributions, Mann-Whitney is superior, often by a large amount. Bridge and Sawilowsky, for example, concluded that" "the t-test was more powerful only under a distribution that was relatively symmetric, although the magnitude of the differences was trivial. In contrast, the [Mann-Whitney] held huge power advantages for data sets which presented skewness" [7]. Many workers have linked results showing the superiority of non-parametric methods for non-normal distributions to claims that data rarely follow a normal distribution (as Micceri puts it: "The unicorn, the normal curve and other improbable creatures" [8]). This has led to implicit recommendations that non-parametric techniques should be considered the method of choice [7].
It is arguable, however, that these prior investigations are flawed. The t-test and Mann-Whitney are used for continuous variables such as blood pressure, depression, weight or pain. Most commonly, we are interested in seeing how these variables change following an intervention. This reflects clinical practice where the patient presents with a problem and asks the doctor to help improve it. In a typical study, a patient with hypertension, obesity or chronic headache is randomized to drug or placebo to see whether the drug is effective for reducing blood pressure, weight or pain. The researchers might report that, say, blood pressure fell by 5 mm in the placebo group but by 14 mm in the drug group. Indeed, trials in which we are interested only in post-treatment scores, and where change is not of interest, are rather rare, being primarily confined to iatrogenic symptoms such as post-operative pain or chemotherapy vomiting.
There are two implications for methodologic research on the relative value of parametric and non-parametric techniques. First, we should worry about the distribution of change scores. It seems likely that change from baseline would approximate more closely to a normal distribution than the post-treatment score. This is because change scores are a linear combination and the Central Limit Theorem therefore applies. As a simple example, imagine that baseline and post-treatment score were represented by a single throw of a die. The post-treatment score has a flat (uniform) distribution, with each possible value having an equal probability (figure 1a). The change score has a more normal distribution: there is a peak in the middle at zero – the chance of a zero change score is the same as the chance of throwing the same number twice, that is 1 in 6 – with more rare events at the extremes – there is only a 1 in 18 chance of increasing or decreasing score by 5 (Figure 1b).

Distribution of scores for a single die roll and the difference between two die rolls. The change score tends towards a more normal distribution.
Moreover, where an endpoint is measured at baseline and again at follow-up, the t-test is not the recommended parametric method. Analysis of covariance (ANCOVA), where baseline score is added as a covariate in a linear regression, has been shown to be more powerful than the t-test [9–11]. It has several additional advantages: it adjusts for any chance baseline imbalances; it can be extended to incorporate randomization strata as co-variates, which has been shown to increase power [12]; it can also be extended to incorporate time effects where measures are repeated.
In this paper, I report results from a study making the more rational comparison between parametric and non-parametric methods: ANCOVA and Mann-Whitney. Such a comparison does not appear to have been reported previously. I aimed to compare relative power of the two methods under a variety of distributions. As a secondary objective, I aimed to determine whether ANCOVA provided an unbiased estimate for the difference between groups where data did not follow a normal distribution. A third, overarching aim was to investigate the distribution of change scores between repeat assessments of a non-normally distributed variable.
Methods
The starting point for this study was to obtain archetypal data sets for analysis. I will follow Bridge [7] in choosing empirical rather than theoretical distributions. I examined the distribution of a large number of empirical data sets and cross-referenced these with those described by Micceri, who systematically obtained 440 data sets from the psychological and educational domains [8]. The most common distribution appeared one with moderate positive skew. As an exemplar, I used a headache severity index from a large (n = 401) randomized trial of headache prophylaxis [13] (Figure 2). This distribution was also used with scores reversed, to create a distribution with moderate negative skew. A second pain data set, this time from a trial on athletes with shoulder pain [14], provides an example of a more uniform distribution (Figure 3). Data on Ki67, an antigen that is a marker for cell proliferation, were obtained from a randomized comparison of two hormonal treatments for breast cancer [15]. The distribution for Ki67 is comparable to Micceri's "extreme asymmetry distribution" (Figure 4). For extreme negative skew, I used data from the physical functioning scale of the SF36 (Figure 5), again taken from the headache trial. As a comparison group, data were also drawn from a normal distribution with a mean of 5 and a standard deviation of 1.

Distribution of post-treatment and change scores from original and simulated data for headache severity ("moderate positive skew" distribution).

Distribution of post-treatment and change scores from original and simulated data for shoulder pain ("uniform" distribution).

Distribution of post-treatment and change scores from original and simulated data for Ki67, a biomarker of cell proliferation ("extreme asymmetry" distribution).

Distribution of post-treatment and change scores from original and simulated data for physical functioning scale of the SF36 ("extreme negative skew" distribution).
For each of the distributions, I created a polynomial that converted normal data to a distribution with an approximately similar shape. For example, the distribution with moderate positive skew in Figure 2 was simulated by sampling x from the normal and creating a new variable equal to 14.8+16.5x+7.5x 2-1.15x 3, rounded, like the original scale, to the nearest 0.25. The simulation distributions were compared to the empirical distributions by visual inspection and comparison of the standard deviation, skewness and kurtosis.
To run the simulations, a bivariate normal (mean 0, standard deviation 1) with a specified correlation was created for a trial of a given sample size equally divided in two groups. The polynomial was applied and a treatment effect introduced. The treatment effect was one of two forms: a shift, for example, scores in the treatment group were reduced by two points; and a ratio, for example, treatment group scores were reduced by 20%. Results were then analyzed by Mann-Whitney and ANCOVA, with p-values obtained by asymptotic approximation for the Mann-Whitney test. In some simulations, t-tests and ANCOVA of log-transformed data were applied. The t-test and Mann-Whitney used the follow-up score if correlation was less than 0.5 and the change score otherwise. This maximizes the power of these tests [11] and might be seen as favoring unadjusted tests on the grounds that the correlation between baseline and follow-up scores is not known when the protocol for statistical analysis is written. Note that the correlation cited in the results is the correlation between baseline and follow-up in the control group. Some previous workers have used the overall correlation using both groups when investigating the properties of ANCOVA [11]. The difference between these two values was small in the context of our simulations, for example, a correlation of 0.5 in the control group was equivalent to a correlation of 0.476 for both groups combined.
Simulations were repeated 1000 times for each combination of sample size (10, 20, 30, 40, 60, 100, 200, 400, 800) and correlation (0.1, 0.2, 0.3 ... 0.9) using Stata 8.2 (Stata Corp., College Station, Texas). The exception was extreme asymmetry data for the Ki67 biomarker. The baseline and post-treatment distributions had quite different shapes and different polynomials were used to model each. This constrained the range of possible correlations, hence only the empirical correlation observed in the original study was used, 0.4, with 5000 iterations.
Results were compared between different methods using the "relative efficiency" (RE) measure. This gives the relative number of patients required for a study analyzed using parametric methods so that power was equivalent to the non-parametric alternative. Hence an RE of 1.25 indicates that a particular trial analyzed by parametric statistics would have to accrue 25% more patients than if it were to be analyzed non-parametrically; an AE of 0.80 would indicate that the parametric method was superior by an equivalent amount. The RE is calculated from observed power of the tests, that is, the proportion of simulations in which the p-value was less than the α of 5%. Where (1-βnp) and (1-βp) are the observed powers from the simulations for the non-parametric and parametric test respectively, RE is given by the formula:
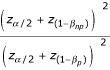
Note that, although it is arguable that the null hypotheses for different tests, say the t-test and Mann-Whitney, are technically different, the conclusions drawn by investigators of a randomized trial given a particular p-value will be the same, regardless of the analytic method used. Hence direct comparison of the power of different tests is justified in this setting.
Results
The figures show the distributions of post-treatment and change scores from the original data and associated simulations. Visual comparison of subfigures (a) with (b), and (c) with (d), suggests that the polynomials used for the simulations produce distributions that are reasonably similar to the related empirical distribution. Comparing subfigures (a) to (c), and (b) with (d), it is apparent that, as hypothesized, the change between baseline and follow-up scores tends towards the normal distribution. These visual impressions are confirmed in Table 1, which shows estimates of the shape parameters for the distributions. The shape parameters for the empirical and simulated data are similar, and skewness is much closer to zero for the change score compared to the follow-up score.
As a second check on the simulations, Table 2 compares the power of t-test and Mann-Whitney. The data for post-treatment scores were obtained by combining all data from simulations where correlation was less than 0.5; the change scores were from data where correlation was 0.5 or more. These results broadly replicate those of previous workers and therefore provide support for the methods of the current study. In particular, the increase in relative efficiency of the t-test under normality (or uniform) is trivial compared to its loss in relative power under asymmetry. Two aspects of Table 2 have not been reported previously. First, RE can vary depending on whether the treatment effect is a shift or a ratio change. Second, the power of Mann-Whitney and t-test are more similar (RE closer to 1) for change scores, presumably because change scores are more normally distributed. An exception is for extreme asymmetry, where Mann-Whitney has extremely poor power for change scores.
Table 3 gives RE for each combination of sample size and correlation for the moderate positive skew data, where the treatment effect was a shift. ANCOVA is generally superior to Mann-Whitney. Smaller sample sizes and correlations near the extremes reduce the advantage of ANCOVA. Table 4 shows the RE for each of the different distributions combining data for correlations between 0.4 and 0.7, which constitutes a typical range for correlations described in the literature [16]. Mann-Whitney is superior for some very small sample sizes, but RE is non-trivially larger than 1 across sample sizes only for the extreme negative skew distribution with a ratio treatment effect. In table 5, data are given by correlation, combining sample sizes. The table has one particularly notable feature: for some distributions, RE's drop dramatically between correlation of 0.4 and 0.5. This is apparently because the endpoint analyzed changed from the post-treatment score to the change score at correlations of 0.5 and above. This was to maximize power following previous work on the power of unadjusted tests based on the normal [9, 11]. As it seems possible that the relative power of analyzing change and post-treatment scores may differ between the normal and asymmetric case, the data were reanalyzed using post-treatment scores only (see Table 6). In the case of extreme negative skew, the simulation was repeated with ANCOVA on log-transformed data. Cleary, analyzing only post-treatment score, irrespective of correlation, improves the efficiency of Mann-Whitney considerably, but it is still inefficient compared to log-transformed ANCOVA. That said, log-transformed ANCOVA is slightly anti-conservative: when the simulation was repeated with no treatment effect, the null hypothesis was rejected for 5.23% (rather than the nominal 5%) of trials.
Table 7 compares the power of Mann-Whitney to ANCOVA on raw and log-transformed data for the distribution with extreme asymmetry. For this distribution, the non-parametric test is generally superior, though there is no simple relationship to sample size. Again, non-parametric analysis of change scores is dramatically less efficient that use of post-treatment scores. To check these data, the methods were used on the original data (n = 185). The p-values for Mann-Whitney on post-treatment scores, Mann-Whitney on change scores, ANCOVA on raw scores and ANCOVA on log-transformed scores were, respectively: 0.0001, 0.672, 0.216 and 0.0003.
Table 8 compares the estimates of treatment effects from ANCOVA with the parameter used to specify the treatment effect. For the distributions with extreme skew, the simulations were repeated without truncation, that is, ignoring maximum and minimum scores. ANCOVA appears to be unbiased where the treatment effect is a shift. Where the treatment effect is a ratio, the estimate given by ANCOVA is effectively the shift expected by a patient with the mean baseline score. The size of the bias under ratio change does not seem to be large and could be adjusted for by incorporating a term for baseline score by treatment interaction.
Discussion
This study complements previous work on the relative power of parametric and non-parametric statistics by examining the common situation where an outcome is measured before and after a randomly assigned treatment. The study also appears to be novel in its incorporation of different types of treatment effect: shift and ratio.
The immediate conclusions challenge the conventional wisdom of the textbooks. There is no simple and obvious manner in which non-parametric methods becomes superior once the distribution of data shifts away from normal. It is true that under normality parametric methods are trivially more efficient. But for non-normal data, the relative power of parametric and non-parametric statistics varies from distribution to distribution and depends on whether the size of the treatment effect depends on baseline score (i.e. a ratio effect). Moreover, there is no simple relationship between relative power and sample size and no clear rationale for the frequently cited threshold of 30 – 50 patients per group indicating acceptability of parametric statistics.
In general, ANCOVA outperformed Mann-Whitney for most distributions under most circumstances. This is heartening because ANCOVA has a major advantage over any non-parametric method: it provides an estimate for the size of the difference between group, that is, an effect size. Clinicians and patients generally want to know not just whether a treatment helps, but how much it helps, so they can determine whether it is worth the time, effort, risks and expense. The CONSORT group, which issues recommendations on the reporting of randomized trials, has stated that the results of a trial should stated as "a summary of results for each group, and the estimated effect size and its precision (e.g., a 95% confidence interval)". They go on to state that "although p-values may be provided ... results should not be re ported solely as p-values" [17]. ANCOVA directly provides the effect size, which appears to be unbiased; Mann-Whitney only the p-value. It is true that an estimate, such as a difference between medians with associated confidence interval, can be calculated separately from the Mann-Whitney and reported alongside the p-value. Nonetheless, the need to use separate techniques for estimation and inference must be seen as a disadvantage. Moreover, the parametric methods are also often to be preferred because estimates using medians may have little relevance for decision making. A good example comes from health economics [18]: we want to know the difference between the mean costs of two treatments because multiplying this difference by the number of patients we expect to treat gives us the expected financial impact of choosing one treatment over the other; the difference in median costs has no practical application.
Accordingly, in apparent distinction to much of the prior methodologic literature, ANCOVA should be the method of choice for analyzing randomized trials with baseline measures. Not only does it do something essential, provide an estimate, that Mann-Whitney cannot, but it appears more powerful in most circumstances. The exception is instructive: Mann-Whitney consistently outperformed ANCOVA only for a data set with extreme skew obtained from a biomarker study. Yet with such extreme skew, the estimate provided by ANCOVA – the average reduction in the biomarker – is of questionable interpretability. Rather than conclude that treatment lead to a 1.5 point drop in Ki67, it seems more appropriate to say that 32% of patients in the treatment group had zero Ki67 at follow-up compared to 14% of controls. In other words, there appears to be a link between the power of ANCOVA and the usefulness of the estimate it provides.
It should be remembered that the relative advantage of ANCOVA is primarily restricted to analysis of randomized trials. It has been argued [19] that ANCOVA with baseline scores should not be used for non-randomized trials on the grounds where baseline scores are not expected to be equivalent. For example, in measuring how anxiety of adolescent boys and girls changes after a stimulus, use of ANCOVA would address the question: "What would be the difference in changes between boys and girls given an equivalent baseline score?". Yet we would not anticipate that baseline anxiety levels of boys and girls would be the same.
This paper has not examined lumpy or multimodal distributions [8]. Yet given that the relative power of parametric methods seems primarily affected by asymmetry – compare the normal and uniform with the skewed distributions – the results cited here should apply to such distributions. This paper also did not examine semi-parametric methods, such as ANCOVA on ranks. There is some evidence that these methods are preferable to fully parametric alternatives for skewed distributions [20] and there remains the possibility of using standard ANCOVA for obtaining estimates of treatment effects and the semi-parametric test for inference.
References
Altman DG: Practical Statistics for Medical Research. London: Chapman and Hall (monograph). 1991.:
Jekel JF, Katz DL, Elmore JG: Epidemiology, Biostatistics and Preventive Medicine. 2001, Philadelphia, W.B. Saunders Company
Heeren T, D'Agostino R: Robustness of the two independent samples t-test when applied to ordinal scaled data. Stat Med. 1987, 6: 79-90.
Sawilowsky SS: Comments on using alternative to normal theory statistics in social and behavioural science. Canadian Psychology. 1993, 34: 432-439.
Zimmerman DW, Zumbo BD: The effect of outliers on the relative power of parametric and nonparametric statistical tests. Perceptual and Motor Skills. 1990, 71: 339-349.
Sawilowsky SS, Clifford-Blair R: A more realistic look at the robustness and Type II error properties of the t test to departures from population normality. Psychological Bulletin. 1992, 111: 352-360. 10.1037/0033-2909.111.2.352.
Bridge PD, Sawilowsky SS: Increasing physicians' awareness of the impact of statistics on research outcomes: comparative power of the t-test and and Wilcoxon Rank-Sum test in small samples applied research. J Clin Epidemiol. 1999, 52: 229-235. 10.1016/S0895-4356(98)00168-1.
Micceri T: The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin. 1989, 105: 156-166. 10.1037/0033-2909.105.1.156.
Senn S: Statistical Issues in Drug Development. 1997, Chichester, John Wiley
Vickers AJ: The use of percentage change from baseline as an outcome in a controlled trial is statistically inefficient: a simulation study. BMC Med Res Methodol. 2001, 1: 6-10.1186/1471-2288-1-6.
Frison L, Pocock SJ: Repeated measures in clinical trials: analysis using mean summary statistics and its implications for design. Stat Med. 1992, 11: 1685-1704.
Kalish LA, Begg CB: Treatment allocation methods in clinical trials: a review. Stat Med. 1985, 4: 129-144.
Vickers AJ, Rees RW, Zollman CE, McCarney R, Smith CM, Ellis N, Fisher P, Haselen RV: Acupuncture for chronic headache in primary care: large, pragmatic, randomised trial. BMJ. 2004, 328: 744-10.1136/bmj.38029.421863.EB.
Kleinhenz J, Streitberger K, Windeler J, Gussbacher A, Mavridis G, Martin E: Randomised clinical trial comparing the effects of acupuncture and a newly designed placebo needle in rotator cuff tendinitis. Pain. 1999, 83: 235-241. 10.1016/S0304-3959(99)00107-4.
Ellis MJ: Neoadjuvant endocrine therapy as a drug development strategy. Clin Cancer Res. 2004, 10: 391S-395S. 10.1158/1078-0432.CCR-031202.
Vickers AJ: How many repeated measures in repeated measures designs? Statistical issues for comparative trials. BMC Med Res Methodol. 2003, 3: 22-10.1186/1471-2288-3-22.
Moher D, Schulz KF, Altman DG: The CONSORT statement: revised recommendations for improving the quality of reports of parallel-group randomized trials. Ann Intern Med. 2001, 134: 657-662.
Thompson SG, Barber JA: How should cost data in pragmatic randomised trials be analysed?. BMJ. 2000, 320: 1197-1200. 10.1136/bmj.320.7243.1197.
Cribbie RA, Jamieson J: Structural equation models and the regression bias for measuring correlates of change. Educational and Psychological Measurement. 2000, 60: 893-907. 10.1177/00131640021970970.
Conover WJ, Iman RL: Analysis of covariance using the rank transformation. Biometrics. 1982, 38: 715-724.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2288/5/35/prepub
Acknowledgements
No outside funding was obtained for this study. Original data for the Ki67 study was kindly provided by Dr Matthew Ellis; data for the shoulder pain study was provided by Dr Konrad Streitberger.
Author information
Authors and Affiliations
Corresponding author
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Vickers, A.J. Parametric versus non-parametric statistics in the analysis of randomized trials with non-normally distributed data. BMC Med Res Methodol 5, 35 (2005). https://doi.org/10.1186/1471-2288-5-35
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2288-5-35
Comments
View archived comments (2)