- Research article
- Open access
- Published:
Imputation by the mean score should be avoided when validating a Patient Reported Outcomes questionnaire by a Rasch model in presence of informative missing data
BMC Medical Research Methodology volume 11, Article number: 105 (2011)
Abstract
Background
Nowadays, more and more clinical scales consisting in responses given by the patients to some items (Patient Reported Outcomes - PRO), are validated with models based on Item Response Theory, and more specifically, with a Rasch model. In the validation sample, presence of missing data is frequent. The aim of this paper is to compare sixteen methods for handling the missing data (mainly based on simple imputation) in the context of psychometric validation of PRO by a Rasch model. The main indexes used for validation by a Rasch model are compared.
Methods
A simulation study was performed allowing to consider several cases, notably the possibility for the missing values to be informative or not and the rate of missing data.
Results
Several imputations methods produce bias on psychometrical indexes (generally, the imputation methods artificially improve the psychometric qualities of the scale). In particular, this is the case with the method based on the Personal Mean Score (PMS) which is the most commonly used imputation method in practice.
Conclusions
Several imputation methods should be avoided, in particular PMS imputation. From a general point of view, it is important to use an imputation method that considers both the ability of the patient (measured for example by his/her score), and the difficulty of the item (measured for example by its rate of favourable responses). Another recommendation is to always consider the addition of a random process in the imputation method, because such a process allows reducing the bias. Last, the analysis realized without imputation of the missing data (available case analyses) is an interesting alternative to the simple imputation in this context.
Background
Patient Reported Outcomes (PRO) nowadays are commonly encountered in clinical research to take into account important unobservable characteristics. They are used for evaluating endpoints that cannot be directly observed and measured, such as Health Related Quality of Life (HR-QoL), anxiety, depressive symptoms, fatigue, addictive behaviors... Usually, patients respond to a questionnaire containing several items, with binary or ordinal responses, and the responses are often combined to give scores. The idea of clinical research is usually to compare two or more groups of patients on different outcomes that can be, for instance, PRO.
Two main types of analysis can be used to handle such data: Classical Test Theory (CTT) and Item Response Theory (IRT). In CTT, the observed scores are assumed to be a good representation of the "true" score. An alternative analysis consists in using IRT models, in which the responses to the items are modelled as a function of a latent variable. This variable is considered to be the ability measured by the questionnaire (e.g. Health Related Quality of Life, anxiety...). Among the IRT models, the Rasch model [1] is the most popular, when all the items have dichotomous responses. Indeed, this model is the most simple one, and allows the derivation of a scale with interesting psychometrical properties. In particular, it is possible to show that the estimations of the latent trait with this model are independant of the retained items. This property of specific objectivity allows the derivation of comparable measures of the latent trait with different versions of the questionnaire (for example, short or long version, with or without missing values....). As a consequence, there are compelling arguments when validating a scale, to retain only those items which show a good fit to a Rasch model [1].
Several indexes allow testing the fit of the Rasch model. As for all the models of IRT, the Rasch model relies on three fundamendal assumptions: undimensionality, local independence and monotonicity. The check of these assumptions can be realized using Loevinger's H coefficients [2, 3], and in particular, the scalability coefficient H. More specifically, the fit of the Rasch model can also be considered. Among the fit tests that have been proposed, the Q1 test [4] is one of the most popular. However, the study of the fit of the Rasch model can only be considered if the parameters of this model are unbiased (parameters characterizing the items, and the parameters of the distribution of the latent variable, since only global measure on the sample will be generally used in clinical research). Last, the fiability of the measure of the latent trait by an IRT model can be evaluated by the Personal Separation Index (PSI) [5]. This index is close, in its interpretation, to the Cronbach's alpha [6], which is a well-known index of reliability in CTT. In the framework of PRO, it is frequent to have a non negligible rate of missing data, which are often non ignorable, because there might be a link between the measured latent variable and the probability of missingness of a response: for instance, patients with worse levels on the latent variable are more likely to have missing responses than other patients [7]. For example, in the case of HR-QoL, patients with a poor quality of life might be too tired to respond to a question or to achieve their questionnaire. This phenomenon can differently influence all the items: some items can be more affected by a large rate of missing data, such as items that deal with a topic that might be difficult to express for the patient. As a consequence, the dataset might contain more information on the patients with a good level on the latent trait, as compared to patients with a poor level, introducing bias into the subsequent analysis.
For this reason, it is important to take into account the occurence of missing data and the possibility of an underlying mecanism of missingness when analysing the dataset. Many authors suggest to replace the missing data by the most probable result: this process is called single (or simple) or multiple imputation [8]. Data are then analysed using these imputed values. Several methods have been proposed to impute missing responses to items, depending on assumptions made on the missing data mechanism. The most popular method for PRO consists in imputing a missing value by the mean response of the patient to the other items. Such a method is clearly recommended in scoring manuals of widely used questionnaires such as SF-36 and QLQ-C30 for instance [9–11]). However, it is well-known that this type of method might be inadequate [12–14], especially when the rate of missing data is high [15].
Nevertheless, such simple imputation methods have been rarely compared in the framework of psychometric validation of PRO questionnaires, especially when an analysis by IRT is planned. Among the few papers on this topic, [16] and [17] compared only a small number of methods, for bias in the estimation of Cronbach's alpha and Loevinger's H coefficient. Sijtsma and van der Ark [17] also considered the fit of the Rasch model. However, the problem of the potential bias on the estimation of the parameters of this model is more important to consider in the first place, because the fit cannot be correctly evaluated with biased parameters.
These two papers focused only on a small number of methods. Moreover, their finding are difficult to compare because different methodologies were used to simulate the missing data. Furthermore, the impact of the imputation methods on the bias in the parameters of parametric IRT models remains unknown. We therefore evaluated the impact of sixteen different methods for handling missing values in the framework of the Rasch model on (i) the bias of commonly used indices for evaluating the fundamental assumptions of IRT (Loevinger's H coefficient), (ii) the bias on the estimated parameters of the Rasch model, (iii) the bias on a fit test statistic, (iv) the bias on the measure of the fiability of the estimation of the latent trait (PSI). These parameters were chosen because they are the most important parameters for validating a Rasch model.
All these investigations were carried out using a simulation study. Such studies can contribute to give more insight from what is known from statistical theory that often provides asymptotic results. Indeed, simulations can be used to reflect real-life situations encountered in practice that can be of interest to applied researchers (various sample sizes, number of items...). Furthermore, simulation studies can help assessing the suitability and precision of different statistical models and in particular the bias in the parameter estimates in relation to a known simulated truth.
We performed a simulation study to evaluate the bias on these parameters or indices, according to the chosen method for handling missing values, the rate of missing values, and whether the missing data were ignorable or not.
Methods
Notation
Let
-
X nj be the dichotomous variable representing the response of the nth individual (n = 1...N) to the jth item (j = 1...J) and x nj its realization [x nj = 0 denotes the more negative response to the jth item and x nj = 1 the positive response]
-
D nj be a dummy variable taking the value 1 if x nj is observed and 0 otherwise and d nj its realization.
-
O n be the set of observed responses for the nth individual
-
M j be the set of observed responses for the jth item
-
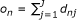 be the number of observed responses for the nth individual
be the number of observed responses for the nth individual -
 be the number of observed responses for the jth item
be the number of observed responses for the jth item -
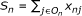 be the score of the nth individual (number of positive non-missing responses)
be the score of the nth individual (number of positive non-missing responses) -
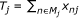 be the number of positive non-missing responses to the jth item
be the number of positive non-missing responses to the jth item -
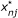 be the possibly imputed value used in the analysis for x
nj
(note that
be the possibly imputed value used in the analysis for x
nj
(note that  if d
nj
= 1)
if d
nj
= 1)
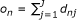 be the number of observed responses for the nth individual
be the number of observed responses for the nth individual be the number of observed responses for the jth item
be the number of observed responses for the jth item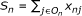 be the score of the nth individual (number of positive non-missing responses)
be the score of the nth individual (number of positive non-missing responses)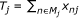 be the number of positive non-missing responses to the jth item
be the number of positive non-missing responses to the jth item if d
nj
= 1)
if d
nj
= 1)Simulation design with (non)informative missing data
Item Response Theory (IRT) [18] is a set of models that allows measuring a latent variable Θ that influences the responses to the items. Three assumptions govern these models:
-
Unidimensionality: only one latent trait influences the responses to all the items,
-
Local Independence: for a given individual, the responses to the items are independent,
-
Monotonicity: the probability of giving a positive response to a given item does not decrease with the latent variable.
Θ is usually considered as a random variable and θ n represents the latent trait of the nth patient. For each patient, the probability of responding to each item is computed according to a specific IRT model, the Rasch model [1]:

where x nj = 0 for a negative response and x nj = 1 for a positive response. δ j is named the difficulty parameter of the jth item, because the higher its value, the lower the probability of positive response. We consider the latent variable as a random variable following a normal distribution with unknown parameters μ and σ 2. This implies that the sample is representative of the underlying population. Using the Local Independence assumption underlying Item Response Theory (IRT), the marginal likelihood is expressed as

with G(Θ/μ, σ 2) the normal distribution function. Note that the Rasch model can be considered as a Generalized Linear Mixed Model with a logistic function as link function.
We estimate δ
j
(j = 1, ..., J), μ and σ
2 by maximizing this marginal likelihood [1]. The integral can be approximated with Gauss-Hermite quadratures. An identifiability constraint must be defined, and generally,  is used, but
is used, but  can also be used. Let
can also be used. Let  is an estimable parameter, meaning that its estimation is independent of the chosen identifiability constraint. In the present paper, the chosen indentifiability constraint is and consequently, a bias on the ν parameter represents a global bias on the δ
j
parameters.
is an estimable parameter, meaning that its estimation is independent of the chosen identifiability constraint. In the present paper, the chosen indentifiability constraint is and consequently, a bias on the ν parameter represents a global bias on the δ
j
parameters.
Three missing data mechanisms have been described by Rubin [19]: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR). For instance, in case of a self-reported HR-QoL questionnaire, data can be considered MCAR if the probability of missing data (missing response on one or more items for instance) is independent of the patient's HR-QoL. Data will be considered MAR if the probability of missing data may depend on covariates describing the patients or on items characteristics [13, 17]. In contrast, data will be considered MNAR if the probability of missing data depends on the patient's (unobserved) HR-QoL.
Data are simulated according to these three mechanisms, following a methodology already proposed by Sébille et al. [20] and close to the one used by Holman and Glas [21] for exploring ignorability of the missing data. More precisly, a latent variable noted ξ is used, corresponding to non-response propensity which represents the tendency of non-response, which varies between individuals. This latent variable may be influenced by the value of the patient's latent trait Θ (HR-QoL, fatigue,...) and may thus involve a non-ignorable non response framework corresponding to MNAR data. To simulate the missing values, we assume that each patient has a non-response propensity to each item represented by the latent variable ξ. The realization of ξ for the nth individual is denoted ξ n .
Let ρ = Corr(Θ, ξ), w a dummy variable (coded 0 or 1) representing the link between the presence of missing data and the difficulty of the items (δ j , j = 1...J), π be the expected rate of missing values for each item and π n be the probability for the nth patient to have a missing value to each item. This probability is assumed to have a lower bound equal to 1% and to be centred on π.

According to the value of ρ and w, different missing data mechanisms could be simulated: for ρ = 0 and w = 0, the missing data will be MCAR, for ρ = 0 and w = 1, they are MAR, and for ρ ≠ 0, the missing data are considered as MNAR. We assume that a patient with a low level on the latent trait (low level of HR-QoL for instance) has a higher propensity to fail to respond to the items, so ρ is assumed to be less than or equal to 0.
Data were simulated with three different values for ρ: ρ = 0 (MCAR or MAR data according to the value of w), ρ = -0.4 (MNAR data with low level of informativity of the missing data) and ρ = -0.9 (MNAR data with high level of informativity of the missing data).
A thousand replications were simulated, each with 500 individuals. Five items were used and the difficulty parameters were fixed to -1, -.5, 0, .5 and 1. The values of θ
n
and ξ
n
were drawn from a standardized normal distribution. Consequently, in all the simulations,  . Three values have been considered for π: 10%, 20% and 30%.
. Three values have been considered for π: 10%, 20% and 30%.
We first simulated complete datasets, then created missing values by the process described above.
Methods for handling missing data in the framework of IRT
No imputation - NOIMP
NOIMP is not an imputation method. It consists in treating all observed data. This method is often referred to as "available case analysis".
Listwise Deletion - LD
LD is not an imputation method either [17]. It consists in omitting the individuals with one or more missing values. This method is often referred to as "complete case analysis".
Worst case - WORST
WORST is a method which consists in substituting the "worst" results to all the missing data. Often, the more negative result is coded 0 (negative response), thus:

Personal Mean Score - PMS and PMS-R
One of the most commonly used methods of imputation in PRO is the Personal Mean Score (PMS) method which involves imputing a missing value using the average score of the individual on the observed responses (rounded to the nearest integer) [16, 17]. This method is used for example for the SF36, which is one of the most popular generic questionnaires of HR-QoL [10, 11] or for the QLQ-C30 [9] which is a questionnaire of HR-QoL in Oncology.

In the PMS-R method, 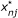 is randomly drawn from a Bernoulli distribution with parameter
is randomly drawn from a Bernoulli distribution with parameter  .
.
Item Mean Score - IMS and IMS-R
This method consists in imputing a missing value with the item mean score (rounded to the nearest integer) [16].

In the IMS-R method, is randomly drawn from a Bernoulli distribution with parameter  .
.
Corrected Item Mean - CIM and CIM-R
PMS only takes into account the ability of the individual, and IMS only takes into account the difficulty of the item. The Corrected Item Mean method is a combination of these two methods: the item mean score is weighted by the personal mean score of the individual [16].

In the CIM-R method, is randomly drawn from a Bernoulli distribution with parameter  .
.
Item Correlation substitution - ICS
This method has two steps: (i) searching for the more correlated item to each item, (ii) if the response of the nth individual to the jth item is missing, we replace it by the response of this individual to the most correlated item to the jth item [16].

with

with X j the variable representing the responses to the jth item (j = 1...J).
Logistic model - LOG and LOG-R
This method consists in fitting a logistic model to each item with missing values, with the other items as covariates [22]. A stepwise selection procedure is subsequently used to iteratively select the items that are significantly related to the missing item, as assessed by the likelihood ratio test.
That is, for an item j with missing values, the following final model is fitted with the items, assuming items k, k ∈ K have been selected with the stepwise procedure (K is the set of the indices of the selected items, j ∉ K):

Where p
nj
= P (X
nj
= 1) and  .
.
In the LOG method, is obtained by rounding the obtained probability, and in the LOG-R method, is randomly drawn from a Bernoulli distribution using this probability as its parameter.
Mokken model - MOK
The imputation by the Mokken model [16, 23] consists in substituting the missing data by the most probable values in order to obtain a responses pattern which produces the fewer Guttman errors as possible (a Guttman error is produced when an individual negatively responds to a given item, and positively responds to a more difficult item). For example, if a large proportion of the sample endorses item A and only a small proportion endorses item B, it is consider inconsistentto have an individual who endorses item B, but not item A.
If the items are ordinated from the most prevalent item to the least prevalent, a coherent vector of responses for a given individual is composed of 1s then of 0s, for example (1,1,1,0,0) or (1,0,0,0,0). The algorithm used for imputation is described here:
-
1.
The items are sorted as a function of the number of positive responses to each of them, from the easiest item (item with the largest amount of positive responses) to the most difficult one.
-
2.
For every missing data the following five rules are applied:
-
(a)
If a positive response follows the missing response, impute the value 1.
-
(b)
If not, then if a negative response precedes the missing response, impute the value 0.
-
(c)
If not, then define a 00 as the number of negative responses preceding a missing response, and a 01 as the number of positive responses preceding a missing response. If a 00 ≥ a 01 impute the value 0.
-
(d)
If not, then define a 10 as the number of negative responses following a missing response, and a 11 as the number of positive responses following a missing response. If a 10 ≤ a 11 impute the value 1.
-
(e)
In all the other cases impute a random draw from the empirical distribution of the dichotomous items, based on their proportion of positive responses.
-
(a)
Rasch model - RAS, RAI and RAS-R
The imputation by the Rasch model consists in susbituting the missing values using the rounded value of the probability of obtaining a positive response predicted by the Rasch model:

In the RAS method, is obtained by rounding pnj, and in the RAS-R method, is randomly drawn from a Bernoulli distribution using p
nj
as its parameter.
These two methods are implemented in the OPLM software [24] to impute missing data in the One Parameter Logistic Model [25], of which the Rasch model is a particular case.
In the RAI (Iterative Rasch model) method, we substitute the missing data by the RAS model, and then reestimate the parameters of the Rasch model with the subsituted values leading to a second substitution. This process is repeated untill two successive iterations give exactly the same substituted values. The algorithm is generally stopped at the 10th iteration.
Summary table
Table 1 summarizes for each method whether it takes into account the ability of the individual, the difficulty of the item, the possibility of a random process or a likelihood based approach (when the imputation is based on a statistical model where the parameters are estimated by a maximum likelihood method).
Note on the imputation process
Imputation of missing data is only carried out for individuals having more than 50% non-missing data (at least 3 responses among the 5 items). This restriction is commonely used in practice, for example for the SF-36 and QLQC30 questionnaires [9, 10] and Sijtsma and van der Ark [17] suggest that this yields more stable results. Note that for the analysis, the individuals with more than 3 missing items are not omitted but only their observed responses have been used.
For the 1000 simulated datasets, using this restriction, imputation could not be performed for an average of 6.0 individuals (over 500 individuals - ~ 1%) when π = 10%, of 37.3 individuals (over 500 individuals - ~7%) when π = 20% and of 97.2 individuals (over 500 individuals - ~ 19%) when π = 30%.
We note that with the ICS, LOG and LOG-R methods, imputation might not be possible in some cases:
• for ICS, if the most correlated item (of an item presenting a missing response) is also missing,
• for LOG(-R), if the logistic model used to fit a missing response includes covariates with missing values.
Studied parameters
We evaluate the impact of the chosen method to handle missing dataon different parameters.
Scalability index
Loevinger's H coefficient [2] is used in non parametric Item Response Theory [3], and measures the scalability of a questionnaire. It can be defined as

with Cov(X j , X k ) the covariance between the items j and k, and Cov (0)(X j , X k ) the maximum possible covariance between these two items with fixed marginal frequencies.
Parameters of the Rasch model
We studied the bias in different ways: the bias in estimating the  parameter, the bias in estimating the variance of the δ
j
parameters
parameter, the bias in estimating the variance of the δ
j
parameters  , and the bias in estimating the variance of the latent trait (σ
2).
, and the bias in estimating the variance of the latent trait (σ
2).
A positive bias on v for instance signifies that the latent trait is underestimated (or that the difficulty parameters of the items are globally overestimated) and corresponds to an optimistic result.
The variance  of the δ parameter is defined by
of the δ parameter is defined by

with  the mean on the 1000 replication of the estimations of the δ
j
parameters. A positive bias on this parameter signifies that the dispersion of the difficulty parameters is overestimated.
the mean on the 1000 replication of the estimations of the δ
j
parameters. A positive bias on this parameter signifies that the dispersion of the difficulty parameters is overestimated.
The variance parameter of the latent trait σ 2 represents the dispersion of the latent trait.
Fit of the Rasch model
In order to evaluate the impact of the imputation methods, we investigated the fit test statistic Q 1 [4]. In this test, we compared for each score the positive responses to each item with the frequencies expected under the Rasch model assumption. Under the null assumption, the statistic follows a chi-square distribution. In this study, we evaluated on the 1000 replications of each case, the rate of rejection of the null assumption "Fit of the Rasch model". This estimation allows evaluating the type-I error of this fit test. It is expected that the rate of rejection of the null assumption will be close to 5% (because the former datasets are simulated with a Rasch model). If the 95% confidence interval does not contain the value 5%, the corresponding imputation method does not allow maintaining the type-I error to its expected level.
Reliability of the estimation of the latent trait
The Personal Separation Index (PSI) is a measure of the reliability of the scale. It can be computed as

where  is evaluated by
is evaluated by

with  being the evaluated standard error of the estimation of the θ
n
parameter.
being the evaluated standard error of the estimation of the θ
n
parameter.
Biases on the parameters
For Loevinger's H coefficient (H) and Personal Separation Index (PSI), the biases in estimating these parameters are computed by comparing the estimation for each replication to the corresponding estimation obtained with complete datasets. For these two estimators, if Ψ is the random variable representing the estimator, we denote ψ
l
the estimation obtained for the lth replication and  the corresponding value with the full dataset. Then,
the corresponding value with the full dataset. Then,

For ν, and σ
2, the bias is computed by comparing the average of the estimations obtained on the 1000 replications to the values used in the simulation design (0 for v, 0.5 for and 1 for σ
2).
The bias is considered as negligible if it is lesser than 0.05 for H and PSI, lesser than 0.1 for v and lesser than 0.2 for . For Q
1, the bias is considered as negligible if the 95% confidence interval of the rate of rejection of the assumption "H
0 : fit of the Rasch Model" contains the value 5%. For σ
2, the bias is considered as negligible if the estimation is included in the interval [0.71; 1.37] that contains 95% of the estimations of σ
2 obtained with the full datasets. Since the bias on σ
2 is computed as  , it is considered as large if it is lesser than 0.71 - 1 = -0.29 or greater than 1.37 - 1 = 0.37, and small otherwise.
, it is considered as large if it is lesser than 0.71 - 1 = -0.29 or greater than 1.37 - 1 = 0.37, and small otherwise.
Software
All analyses were done using Stata software. Loevinger's H was computed with the -loevh- command [26] (using the pairwise option), and the parameters of the Rasch model were estimated with -raschtest- [27] commands. The simulations were carried out with the -simirt- module. Three Stata modules (-imputeitems-, -imputerasch- and -imputemok-) were written to impute the missing data. All these Stata modules can be downloaded from the website of the first author http://www.anaqol.org.
Results
The results given in this section are based on the mean results of the 1000 replications of each case. Formal statistical tests have been carried out to determine potential π and ρ effects for each imputation method on the bias of each studied parameter. In the event, all the tests were statistically significant, which raises the problematic issue of the distinction between statistically significant results and meaningfull results or results of practical importance. This is why, the above mentioned thresholds are proposed to help determine small and large bias.
The standard errors of the evaluations of all parameters have been computed, but, since they remained very stable whatever the values of π, ρ and the missing data mechanism (MCAR, MAR, MNAR), they were not included in the tables.
Tables 2 to 7 present respectively the bias in estimating the Loevinger's H coefficient (table 2), the v (table 3), (table 4) and σ
2 (table 5) parameters, the rate of rejection of the Rasch model by the Q1 test (table 6) and the bias in estimating the PSI (table 7), for all the studied values of the w, π and ρ parameters.
MCAR and MAR cases
Bias is encountered for all methods in the MCAR (w = 0 and ρ = 0) and MAR (w = 1, ρ = 0) cases, but to a different extent. For all the methods and all the studied parameters, the bias increases with π, although for some methods, the bias can be small even for high values of π.
With the exception of IMS and LOG, all the methods that do not incorporate a random process (PMS, ICS, CIM, MOK, RAS, RAI, WORST) present bias on the majority of the parameters (at least 3 among the 6 studied parameters) in these two cases. IMS presents small bias in the MCAR case (only for and PSI), but is more biased in the MAR case. This result could be expected because IMS is the only imputation method (with WORST) that does not incorporate the difficulty of the items in the imputation process.
If the methods using a random process are generally better than the similar methods with no random process, only LOG(-R), RAS-R, NOIMP and LD present few bias on the majority of the parameters in the MCAR and MAR cases. For these methods, we note a higher rate of rejection of the Rasch model than exepcted, a bias on (for LOG(-R) and RAS-R), or on the PSI (for LOG and NOIMP). LD is the only method that dispays a rate of rejection of the Rasch model which is significantly lesser than 5%. This phenomenon can be explained by the fact that LD omits all the individuals with at least one missing value, and consequently, the number of remaining individuals is smaller as compared to the others methods. As a consequence, the Q1 test, which is a chi-square type test, might lack power to detect small deviations to the Rasch model.
On the opposite, MOK, CIM and WORST present a relevant bias on all the parameters except ν in the MCAR and MAR cases, and PMS, RAS and RAI are very biased methods in the MAR case.
MNAR cases
All the methods present several bias in the MNAR case (ρ ≠ 0). For all the methods and all the studied parameters, the bias increases with π, even if for some methods, the bias can be negligible even for high values of π. Generally, the effect of the ρ parameter is smaller (except for WORST or LD) and can reinforce or reduce the bias when ρ increases in absolute value.
NOIMP, LOG-R, and RAS-R are the three methods that produce the smallest number of biased parameters in the MNAR case. Indeed, if the rate of missing value is weak (π = 10%), RAS-R is unbiased on all the studied parameters, and LOG-R and NOIMP are biased only on the rate of rejection of the Rasch model. Neverthless, when the rate of missing value is larger than 10%, these three methods present bias on the rate of rejection of the Rasch model, NOIMP and LOG-R present bias on v and PSI, and RAS-R present bias on .
For the methods PMS, IMS, CIM, LOG and RAS, the addition of a random process in the imputation process seems to reduce the bias on all the parameters. As for the MCAR and MAR cases, LD is the only method that produces a too lower rate of rejection of the Rasch model than expected, and this could be explained by the number of individuals used with this method. WORST and RAI produce a systematic relevant bias on all the studied parameters, and PMS, CIM, MOK and RAS displaya relevant bias on 5 of the 6 studied parameters.
Discussion
Sixteen methods for handling missing data have been investigated in the framework of psychometric validation of a PRO scale using IRT-based methodology. Several situations were considered according to the type of missing data one might encounter in practice: namely MCAR, MAR or MNAR type of missing data.
Some of the investigated methods can be referred to as principled methods, mostly relying on likelihood-based analysis, such as Rasch models or on an handling of the missing data without imputation, such as NOIMP or LD and others as unprincipled or ad-hoc methods such as PMS, IMS, CIM or WORST. Some of the latter methods (PMS, IMS) are frequently used for missing data imputation in HR-QoL scales even though they are known to provide biased estimations [28] in cross-sectional or longitudinal settings. By contrast, the former principled methods are likely to be consistent under MCAR and sometimes MAR mechanisms.
As expected, we observed that principled methods such as NOIMP and LD were rarely biased (except regarding the Q1 test) under MCAR and MAR mechanisms whatever the amount of missing data. By contrast, unprincipled methods such as PMS, CIM, ICS, MOK or WORST were almost systematically biased even under MCAR and MAR mechanisms. More precisely, most of the methods taking into account the ability of the individuals in the imputation process tend to overestimate the psychometric quality of the scale (measured for example by the Loevinger's H coefficient or the PSI). This result was already noted by Huisman [16] and reflects the fact that these methods assume good properties of the scale and hence, tend to incorrectly enhance its psychometric performance during imputation.
Moreover, the methods incorporating the ability of the individual also overestimated the variance of the latent trait (σ 2) thus creating artificial heterogeneity between the individuals. As a matter of fact, such methods will more likely impute a negative (positive) response to a patient who's observed score is low (high) and consequently falsely amplify the distance between individuals on the latent trait scale. In most cases, the addition of a random process helped to diminish the bias quite importantly and should be systematically used when possible [29].
The impact of the imputation methods in terms of bias was usually intensified under MNAR mechanism except for NOIMP, LOG-R and RAS-R that displayed the most robust results and remained usually unbiased (bias, if present, remained rather slight when π < 20%). However, this time, LD was also affected and displayed bias, especially on the ν and item difficulties variance parameters . Moreover, the type I error of the goodness-of-fit Q1 test was underestimated for LD when the amount of missingness was high (π = 30%), possibly reflecting a loss in power. It is well known that MNAR missing data may importantly affect the representativeness of a study sample in relation to the target population. In this study, MNAR missing data were simulated such as patients with lower level on the latent trait (reduced HR-QoL for instance) had a higher non response propensity. The likelihood of missing data could also be larger as the item difficulties increased. As a consequence, in case of MNAR data, the data suffer from sample selection bias: for instance, patients having the highest levels on the latent trait primarily remained in the study and, under some circumstances, the easiest items were more often answered to. This leads to usually overestimate the latent trait level (and jointly underestimate item difficulties) producing negative bias for the v parameter except for the WORST method that systematically underestimates the latent trait level by only imputing negative responses. A ρ effect was observed for most of the methods on v (except for CIM(-R)) and it could sometimes be quite large. This effect, reflecting the strong informativity of the missing data, generally enlarged the bias that was already observed except for the WORST method for which the bias was attenuated but still remained.
Although one could expect poor results using such unprincipled or ad-hoc simple imputation methods for handling missing data, little was known about the impact of using one method or another on the quality of questionnaire validation studies. Indeed, missing data are solely described in such studies for assessing acceptability of a questionnaire [30, 31] and PMS or IMS-based methods are often used for imputation. As a matter of fact, one of the most commonly used imputation method in a wide range of PRO studies (validation or clinical research studies), namely PMS, displayed poor properties regarding bias on a large number of parameters whatever the studied situation (MCAR, MAR or MNAR data) and the amount of missing data. As a consequence, this method should be avoided because it is very likely to overestimate the psychometric qualities of scales. Furthermore, PMS might also decrease the power of a test aimed at comparing two groups of patients on a PRO measure by artificially increasing the variance of the latent trait. This is in line with other authors such as Chavance [22] who recommends the use of this imputation method only if the rate of missing values is small (inferior to 5%). Moreover, Fayers et al. [32] gave six conditions for using PMS, which are rarely present from a practical point of view.
The methods based on Rasch models without a random process (RAS and RAI) often displayed poor results regarding bias on several parameters, especially on the variance of the latent trait that was overestimated along with the dispersion of the parameters difficulties that was underestimated. It was unforeseen that these possibly attractive methods should in fact be avoided, even though it was already noted, but not formally evaluated by Sijtsma and van der Ark [17].
The analysis without imputation NOIMP is a good alternative to simple imputation, provided all the responses are used in the analysis, under MCAR, MAR and even MNAR data. This result could be expected because one of the most important properties of the Rasch model is the specific objectivity. This property yields that i) all estimated difficulty parameters are independent of the sample used for estimation (item parameter invariance), ii) all latent trait related parameters are also independent of the items used for estimation (person parameter invariance). Consequently, the estimations of the parameters are consistent, even with an incomplete dataset, and whatever the type of missing data. However some specificities of this study have to be mentioned: Loevinger's H coefficient has been computed by pairwise technique which consists in using all the contingency tables between each pair of items in order to compute this indice (the usual procedure consists in estimating this indice by listwise deletion). The same remark can be made concerning the parameters of the Rasch model that have been estimated by marginal maximum likelihood allowing taking into account all observed responses. Other methods of estimation (conditional maximum likelihood for example), omitting the individuals with one or several missing data, might end to poorer results.
Our study focused on simple imputation methods that are frequently encountered in practice in most studies aiming at validating or analysing PRO data. An important issue with such methods is that they will often lead to a misleading estimation of precision, which is often overestimated. Since our major objective was to highlight the strong deleterious impact that these methods also have in the framework of studies aiming at validating PRO scales, other alternative for handling missing data were not evaluated. This is the case of hot deck substitution [16, 33], imputation based on the Response Function Imputation [17], and Two-way imputation [17, 34]. Moreover, we have not tested multiple imputations methods, which are recommended by several authors [8, 15, 17], in order to provide valid inferences for statistical estimates from incomplete data and more stable results. However, under MCAR or MAR, multiple imputations should lead to analyses that are similar to likelihood based analyses, being asymptotically equivalent as the number of imputations increase.
Conclusion
This study shows that the choice of the imputation method must be made with attention during the validation of a scale by a Rasch model in presence of missing data. If the missing data are suspected to be MCAR or MAR, several principled methods could be used, like RAS-R, NOIMP or LD methods. However, if the missing data are suspected to be MNAR, RAS-R or NOIMP might be preferred (and LD must be avoided), but it seems sensible to realize the analysis only if a small number of missing data (π = 10%) is present. If the number of missing data is too large, none of the methods used to handling missing data seems to produce accurate results on the majority of the parameters, and consequently, all the analyses might be biased. One can also stress that all the methods not including a random process, in particular PMS (that is the most popular method), should be disregarded.
Finally, the impact of the choice of an imputation method on the statistical properties of tests aimed at comparing PRO data from two groups of patients is also an important topic for future research and deserves investigation.
References
Fisher GH, Molenaar IW: Rasch Models, Foundations, Recent Developments, and Applications. 1997, New-York: Springer-Verlag
Loevinger J: The technic of homogeneous tests compared with some aspects of scale analysis and factor analysis. Psychological Bulletin. 1948, 45: 507-529.
Sijtsma K, Molenaar IW: Introduction to Nonparametric Item Response Theory. 2002, Thousand Oaks, CA: Sage Publications
van den Wollenberg AL: Two new test statistics for the Rasch model. Psychometrika. 1982, 47: 123-140. 10.1007/BF02296270.
Andrich D: An Index of Person Separation in Latent Trait Theory, the Traditional KR-20 Index, and the Guttman Scale Response Pattern. Education Research and Perspectives. 1982, 9: 95-104.
Cronbach LJ: Coefficient alpha and the internal structure of tests. Psychometrika. 1951, 16 (3): 297-334. 10.1007/BF02310555.
Curran D, Bacchi M, Shmitz SF, Molenberghs G, Sylvester RJ: Identifying the types of missingness in quality of life data from clinical trials. Statistics in Medicine. 1998, 17 (5-7): 739-756. 10.1002/(SICI)1097-0258(19980315/15)17:5/7<739::AID-SIM818>3.0.CO;2-M.
Van Buuren S: Multiple imputation of discrete and continuous data by fully conditional specification. Statistical Methods in Medical Research. 2007, 16 (3): 219-242. 10.1177/0962280206074463.
Aaronson NK, Ahmedzai S, Bergman Bea: The European Organization for Research and Treatment of Cancer QLQ-C30: A quality-of-life instrument for use in international clinical trials in oncology. Journal of the National Cancer Institute. 1993, 85 (5): 365-376. 10.1093/jnci/85.5.365.
Ware JE, Sherbourne CD: The MOS 36-item short form health survey (SF-36). I. Conceptual framework and item selection. Medical Care. 1992, 30: 473-483. 10.1097/00005650-199206000-00002.
Leplege A, Ecosse E, Pouchot J, Coste J, Perneger T: Le questionnaire MOS SF-36 - Manuel de l'utilisateur et guide d'interprétation des scores. 2001, Paris: Estem
Fielding S, Fayers PM, McDonalds A, McPherson G, Campbell MK: Simple imputation methods were inadequate for missing not at random (MNAR) quality of life data. Health and Quality of Life Outcomes. 2008, 6 (57): 1-57.
Molenberghs G, Kenward MG: Missing data in Clinical Studie. 2007, Chichester: Wiley
Molenberghs G, Thijs H, Jansen I, Beunckens C, Kenward MG, Mallinckrodt C, Carrol RJ: Analyzing incomplete longitudinal clinical trial data. Biostatistics. 2004, 5 (3): 445-464. 10.1093/biostatistics/kxh001.
Shrive FM, Stuart H, Quan H, Ghali WA: Dealing with missing data in a multi-question depression scale: a comparison of imputation methods. BMC Medical Research Methodology. 2006, 6 (57): 1-10.
Huisman M: Imputation of missing item responses: Some simple techniques. Quality & Quantity. 2000, 34 (4): 331-351. 10.1023/A:1004782230065.
Sijtsma K, Van Der Ark LA: Investigation and Treatment of Missing Item Scores in Test and Questionnaire Data. Multivariate Behavioural Research. 2003, 38 (4): 505-528. 10.1207/s15327906mbr3804_4.
Linden WJVD, Hambleton RK: Handbook of Modern Item Response Theory. 1997, New-York: Springer-Verlag
Rubin DB: Inference and missing data. Biometrika. 1976, 63: 581-592. 10.1093/biomet/63.3.581.
Sébille V, Hardouin JB, Mesbah M: Sequential analysis of latent variables using mixed-effect latent variable models: Impact of non-informative and informative missing data. Statistics in Medicine. 2007, 26: 4889-4904. 10.1002/sim.2959.
Holman R, Glas CAW: Modelling non-ignorable missing-data mechanisms with item response theory models. British Journal of Mathematical and Statistical Psychology. 2005, 58: 1-17.
Chavance M: Handling Missing Items in Quality of Life Studies. Communications in Statistics. Theory and Methods. 2004, 33: 1371-1384. 10.1081/STA-120030155.
Laros JA, Tellegen PJ: Construction and validation of the SON-R 5 1/2-17, The Snijders-Oomen non verbal intelligence test. 1991, Groningen: Wolters-Noordhoff
Verhelst ND, Glas CAW, Verstralen HHFM: One-parameter logistic model OPLM. 1995, Arnhem: CITO
Verhlest ND, Glas CAW: The One Parameter Logistic Model. Rasch Models, Foundations, Recent Developments, and Applications. Edited by: Fischer GH, Molenaar IW. 1997, New York: Springer-Verlag, 215-238. 2
Hardouin JB, Bonnaud-Antignac A, Sébille V: Non Parametric Item Response Theory using Stata. The Stata Journal. 2010, 10: to appear
Hardouin JB: Rasch analysis: estimation and tests with the Raschtest module. The Stata Journal. 2007, 7: 22-44.
Little RJA, Rubin DB: Statistical Analysis with Missing Data. 2002, New-York: Wiley
Nap RE: Missing Data: different forms of imputation methods and their application to empirical data sets. Research report VSM-94-01-SW, Departement of Statistics & Measurement Theory. 1994, Groningen: University of Groningen
Kahn SR, Lamping DL, T D, Arsenault L, Miron MJ, Roussin A, Desmarais S, Joyal F, Kassis J, Solymoss S, Desjardins L, Johri M, Shrier I: VEINES-QOL/Sym questionnaire was a reliable and valid disease-specific quality of life measure for deep venous thrombosis. Journal of Clinical Epidemiology. 2006, 59 (10): 1049-1056.
Sinfield P, Baker R, Tarrant C, Agarwal S, Colman AM, Steward W, Kockelbergh R, Mellon JK: The Prostate Care Questionnaire for Carers (PCQ-C): reliability, validity and acceptability. BMC Health Serv Res. 2009, 9: 229-10.1186/1472-6963-9-229.
Fayers PM, Curran D, Machin D: Incomplete Quality of Life data in randomized trials: missing items. Statistics in Medicine. 1998, 17: 679-696. 10.1002/(SICI)1097-0258(19980315/15)17:5/7<679::AID-SIM814>3.0.CO;2-X.
Allison P: Missing Data. 2002, Thousand Oaks: Sage
Bernards CA, Sijtsma K: Influence of imputation and EM methods on factor analysis when item nonresponse in questionnaire data is nonignorable. Multivariate Behavioral Research. 2000, 35: 321-364. 10.1207/S15327906MBR3503_03.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2288/11/105/prepub
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
JBH have made substantial contributions to conception and design, acquisition of data, analysis and interpretation of data. VS have made substantial contributions to conception and design, analysis and interpretation of data. RC have made substantial contributions to interpretation of data. All authors read and approved the final manuscript.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Hardouin, JB., Conroy, R. & Sébille, V. Imputation by the mean score should be avoided when validating a Patient Reported Outcomes questionnaire by a Rasch model in presence of informative missing data. BMC Med Res Methodol 11, 105 (2011). https://doi.org/10.1186/1471-2288-11-105
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2288-11-105